
Russian Learner Translator Corpus (Russian LTC) или Корпус учебных переводов - это доступная для скачивания коллекция студенческих переводов в паре английский-русский (оба направления).
Разработка корпуса началась в 2011 сотрудниками кафедры перевода и переводоведения ТюмГУ. К 2014 году при поддержке компьютерных лингвистов из Высшей школы экономики (Москва) корпус превратился в полноценный публичный ресурс с собственным веб интерфейсом, статистическим сервисом и системой разметки переводческих ошибок. В 2017 исследовательский проект, отчасти основанный на данных RusLTC, получил поддержку РФФИ (проект No 17-06-00107 «Лингвистические признаки русскоязычного переводного дискурса: дескриптивные нормы и оценка качества текста»
В корпус включаются переводы, выполненные студентами специальности «Перевод и переводоведение» и дополнительной квалификация «Переводчик в сфере профессиональной коммуникации» (очное и очно-заочное отделения), направлений подготовки бакалавриата «Лингвистика» (вид деятельности: переводческая), а также переводы, представленные к участию в нескольких российских конкурсах перевода. RusLTC содержит переводы студентов из 14 российских вузов (НГЛУ, МГУ, ПГНИУ, УдГУ, СГУ, ЧелГУ, КГПУ им. В.П Астафьева и др). Все переводы анонимизированы. Об авторе перевода хрянятся только общие сведения: пол, курс, форма обучения, год выполнения перевода, которые включены в дополнительные параметры поиска на главной странице корпуса.
Корпус пополняется два раза в год, и по состоянию на 16 октября 2018 года его общий объем составляет более 2,3 млн словоупотреблений. Общее количество английских оригиналов - 402, русских оригиналов - 125. Количество переводов к каждому из них варьирует от 1 до 67 и в среднем составляет 8. Чаще всего студенты переводя предложенные фрагменты оригинала: средняя длина переводов на русский язык составляет 380 слов. Более подробную информацию о статистических параметрах корпуса, которая обновляется в режиме реального времени, можно получить по адресу: https://dev.rus-ltc.org/statistics/
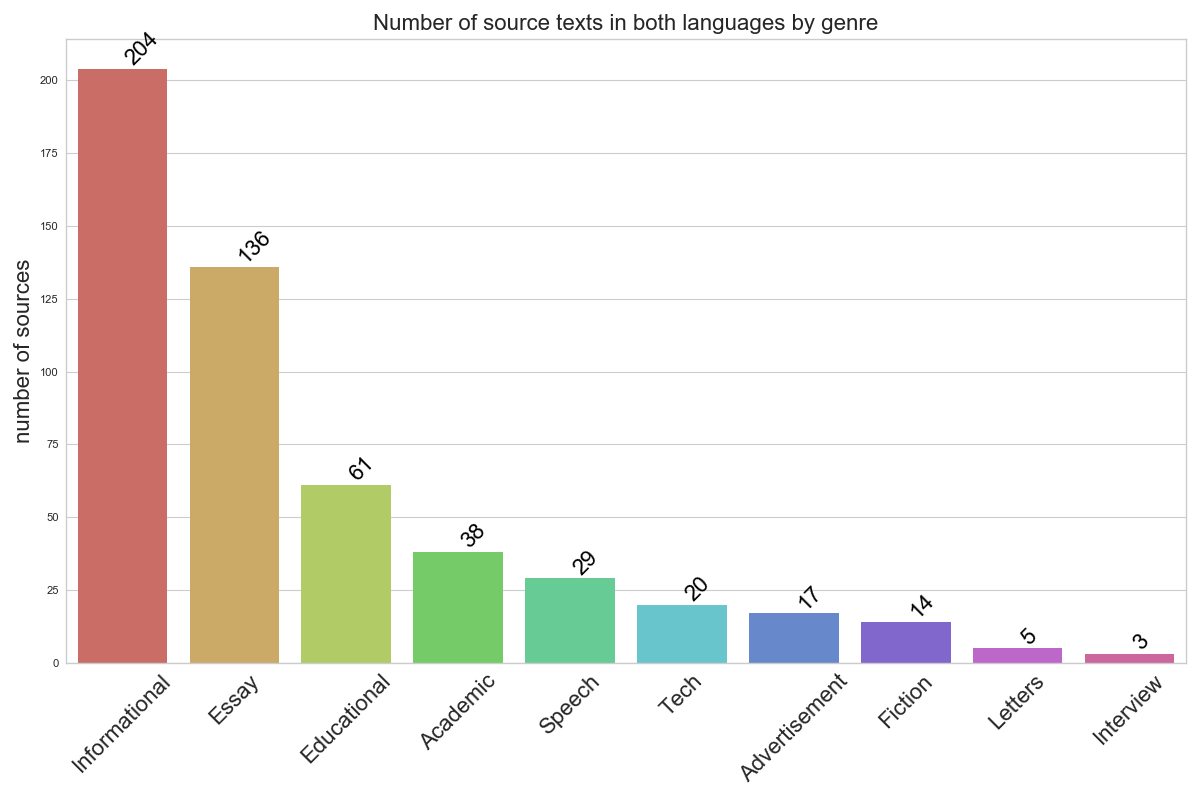
Корпус существует в двух форматах. Во-первых, он представляет собой коллекцию соотнесенных по именам файлов оригиналов и их (нескольких) переводов, а во-вторых тот же материал существует в двуязычном формате TMX: как стуктура, в которой к каждому предложению оригинала привязаны все его переводы. С сентября 2018 года поисковой интерфейс RusLTC основан на корпусном менеджере Тимофея Архангельского Tsakorpus. Он позволяет строить лексические, лексикограммитические и лемматизированные запросы, проводить поиск в оригиналах или переводах, а в результатах отображать все, связанные с исходным, предложения на другом языке. Кроме того, можно проводить поиск по более однородной группе текстов, сформировав подкорпус по метаданным о переводчике, о тексте оригинала и о ситуации перевода (кнопка Select Subcorpus). Полный список метаданных включает 10 параметров (для некоторых текстов тот или иной вид данных может отсутствовать): пол переводчика, вид и ступень образовательной программы, оценка за перевод, год и условия выполнения перевода (дома/в классе; экзамен/текущий перевод/конкурс), жанр оригинала, университет. Все оригиналы в корпусе отнесены к одной из следующих жанрово-регистровых разновидностей: информационный, публицистический, научный, научно-популярный, художественный, речь, письмо, реклама (см. рисунок справа, отображающий жанровое распределение текстов в корпусе).
Например, можно определить отличается ли частотность бытийных глаголов "существовать, быть, являться, иметься" в переводах начинающих переводчиков и старшекурсников. Действительно ли в более высоко оцененнных переводах меньше указательных местоимений, а "enjoy" и "everyone" это необязательно "наслаждаться" и "каждый"? Характерна ли для студентов тенденция калькировать типичные английские способы выражения эпистемической модальности I think, I believe? Небезынтересно взглянуть на аналитические пассивы в переводном русском языке - их образуют от самых неожиданных глаголов! Часто ли "на самом деле", "однако" и "кроме того" добавлены переводчиком для экспликации логических связей между частями текста? Удаётся ли студентам преодолеть влияние оригинала и уйти от буквальных способов перевода инфинитива в функции определения (N+to+V) или в функции сопутствующего обстоятельства (в русскоязычных переводах: ", чтобы V"?
Результаты поиска можно сохранить в виде файла в формате csv.
Корпус преимущественно используется для исследований в области вариативности и качества перевода, для изучения особенностей становления профессиональной переводческой компетенции, лингвистической специфичности переводов в целом, для выявления типичных переводческих проблем и проверки гипотез относительно теоретических переводческих трудностей, традиционно описываемых на основе сопоставительных данных (способы передачи эпистемической модальности, «ложные друзья переводчика» и пр.)
Сравнительно небольшая часть RusLTC (599 переводов на русский и 166 – на английский на февраль 2018 года) размечена по ошибкам при помощи программы текстовых аннотаций brat (Stenetorp et al 2012). Аннотации хранятся в отдельном файле. Идентификация размеченного сегмента производится по порядковаму номеру первого и последнего символа выделенного фрагмента. Разметка производится на основе специально созданной классификации переводческих ошибок, включающей 30 иерархически организованных типов ошибок. Кроме того, аннотатор может отметить "вес" ошибки и ее технологическую преичину, а также оставить комментарий (см. инструкцию по разметке и подробное описание таксономии ошибок). Разметка ошибок используется в курсе практического перевода, поэтому объем размеченных данных растет естественным образом (На октябрь 2018 всего размечено 765 переводов, из них в англо-русской части - 599 (объемомм 230 K слов) к 72 оригиналам. Посмотреть размеченные переводы можно по адресу https://dev.rus-ltc.org/brat/#/rusltc/.
RusLTC можно скачать в двух вариантах: (1) в виде двуязычного файла в формате доработанного TMX (разновидность XML, использующаяся для хранения памяти перевода в системах автоматизированного перевода) или (2) в виде архива простых текстовых файлов в кодировке Unicode utf-8.
Каждому тексту присваивается уникальное имя, содержащее следующие элементы: обозначение языка, на котором он написан (EN или RU), номер одного из разработчиков корпуса, уникальный номер для каждого оригинала (независимо от языка оригинала) и, в случае переводов, порядковый номер перевода для одного оригинала. Например, имя файла RU_1_35.txt означает, что это оригинал на русском языке из раздела, курируемого разработчиком 1, а EN_1_35_3.txt – это перевод указанного оригинала под номером 3.
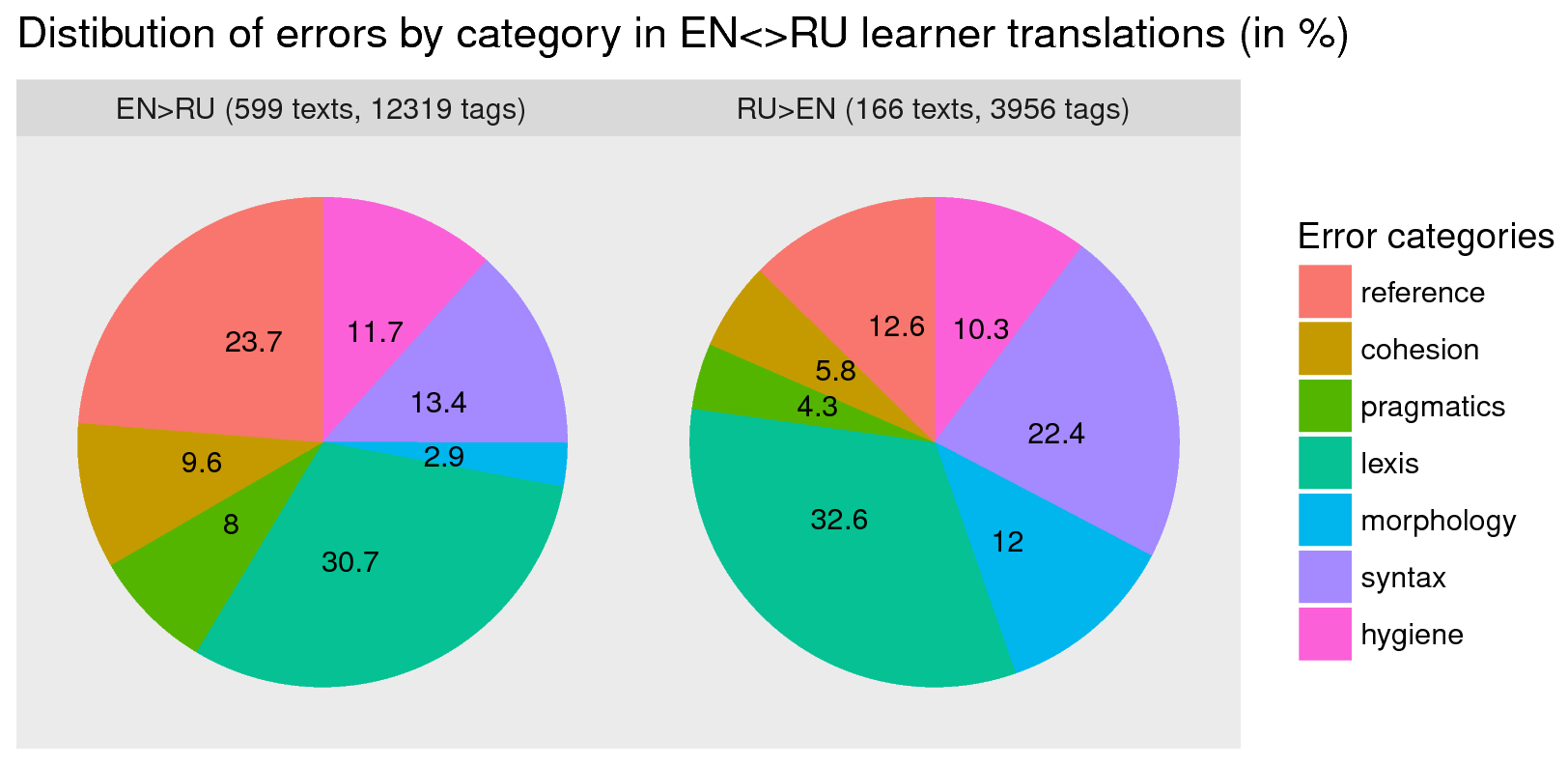
Все метаданные и разметка по ошибкам к каждому переводу хранятся в одноименных служебных файлах, снабженных уточнением head или расширением ann (напр., RU_1_35.head.txt содержит метаданные к указанному тексту, а EN_1_35_3.ann – разметку по ошибкам). Обобщенная статистика по видам выделенных ошибок представлена на рисунке слева.
Контент корпуса (оригиналы и переводы, а также метаданные) доступен под свободной лицензией Creative Commons Attribution-ShareAlike. Вы можете использовать его в любых целях, при условии ссылки на авторов корпуса (Kunilovskaya, Kutuzov 2014 в списке литературы ниже) и распространении вашей производной работы под аналогичной свободной лицензией.
Если вы являетесь автором одного из включенных в корпус текстов или переводов и не желаете, чтобы он был доступен в Сети, то свяжитесь с авторами корпуса и мы удалим ваше произведение из свободного доступа. Насколько нам известно, RusLTC – единственный множественный параллельный корпус учебных переводов, доступный онлайн и включающий русский язык. В мире это третий (и самый большой) параллельный корпус в Интернете, после ENTRAD and MeLLANGE LTC (см. Таблицу 1, в которой описаны все аналогичные ресурсы по состоянию на март 2014).
Если у вас возникли вопросы пишите нам на электронную почту mkunilovskaya@gmail.com.
Скачать корпус как набор текстовых файлов с мета-данными
Скачать корпус как выровненный TMX-файл (bitext)
Подробнее о корпусе и о результатах наших исследований можно прочитать в следующих публикациях:
Dialogue 2017(pp. 221-233) Appendix 1. Semantic taxonomy of connectives
Презентация корпуса на конференции TSD-2014, Брно, Чехия:
